library(vegan)
library(ggplot2)
## mean-corrected lognormal abundances: E[abundance] = lambda for every group,
## so groups can share an identical expected composition while differing only in spread
gen_group <- function(n, sig, lambda) {
nsp <- length(lambda)
M <- matrix(0, n, nsp)
for (i in 1:n) M[i, ] <- round(lambda * exp(rnorm(nsp, 0, sig) - sig^2 / 2))
M[M < 0] <- 0
M
}Four common PERMANOVA mistakes in ecology
R
vegan
multivariate
PERMANOVA
ecology tutorial
A significant PERMANOVA can really be unequal dispersion. Check betadisper, pick the right dissimilarity, respect your design, and read adonis2 honestly.
PERMANOVA, run through vegan::adonis2, is the default tool for asking whether community composition differs between groups. It is powerful, assumption-light, and easy to call, which is exactly why it is so often misread. A small p value feels like a clean verdict that composition differs. It is not, on its own, any such thing. This post works through the four mistakes that most often turn a PERMANOVA into a confident wrong conclusion, with the first one being by far the most important.
Mistake 1: reading a significant result as a location difference
PERMANOVA partitions the total sum of squared dissimilarities into a between-group and a within-group part and forms a pseudo-F. The trouble is that the between-group term responds to two quite different things at once: a shift in the group centroids (a location, or composition, difference, which is what you usually mean), and a difference in how spread out the groups are (a dispersion, or beta-diversity, difference). A pseudo-F can be large because the centroids moved, because one group is far more variable than the other, or both. The test alone cannot tell you which.
This matters because the two have completely different ecological meanings, and because of a subtle geometric fact: in Bray-Curtis space, groups with identical mean abundances but different dispersions develop genuinely separated centroids. Anderson and Walsh demonstrate this directly; unequal variability in the original abundance space shows up partly as a centroid shift once you compute dissimilarities. So a dispersion difference does not just inflate the residual; it leaks into the between-group term and can make PERMANOVA reject when nothing about the mean composition changed.
Here are two groups drawn from the same twelve-species mean-abundance vector. The only difference is that group B is far more variable from site to site.
set.seed(101)
nsp <- 12
lambda1 <- exp(seq(log(3), log(45), length.out = nsp))
Y1 <- rbind(gen_group(30, 0.30, lambda1), # group A: tight
gen_group(30, 1.10, lambda1)) # group B: diffuse, identical expected composition
g1 <- factor(rep(c("A", "B"), each = 30))
D1 <- vegdist(Y1, method = "bray")Run PERMANOVA, then immediately run the dispersion test that should always accompany it, betadisper.
ad1 <- adonis2(D1 ~ g1, permutations = 999)
c(F = round(ad1$F[1], 2), R2 = round(ad1$R2[1], 3), p = ad1$`Pr(>F)`[1]) F R2 p
4.640 0.074 0.001 bd1 <- betadisper(D1, g1)
an1 <- anova(bd1)
c(F = round(an1$`F value`[1], 1), p = signif(an1$`Pr(>F)`[1], 3)) F p
2.108e+02 5.720e-21 round(tapply(bd1$distances, g1, mean), 3) # mean distance to group centroid A B
0.110 0.349 PERMANOVA returns a significant result (p around 0.001) with an R squared of about 0.07. Taken alone you would report that composition differs between groups. But betadisper is overwhelmingly significant, with an F over 200, and the mean distance to centroid is 0.11 for group A against 0.35 for group B. The groups are not centred in different places by design; one is simply three times more dispersed than the other, and that heterogeneity is what PERMANOVA picked up. The small R squared is the tell: a real composition shift of ecological interest rarely hides at 7 percent while the dispersion test screams.
Now the honest case: a real composition shift, with dispersion held equal.
set.seed(202)
lambdaA <- exp(seq(log(3), log(45), length.out = nsp))
lambdaB <- lambdaA
lambdaB[1:4] <- lambdaB[1:4] * 4 # boost the rare species
lambdaB[9:12] <- lambdaB[9:12] / 4 # suppress the common ones
Y2 <- rbind(gen_group(30, 0.6, lambdaA),
gen_group(30, 0.6, lambdaB)) # same sigma in both groups
g2 <- factor(rep(c("A", "B"), each = 30))
D2 <- vegdist(Y2, method = "bray")ad2 <- adonis2(D2 ~ g2, permutations = 999)
c(F = round(ad2$F[1], 2), R2 = round(ad2$R2[1], 3), p = ad2$`Pr(>F)`[1]) F R2 p
49.070 0.458 0.001 bd2 <- betadisper(D2, g2)
an2 <- anova(bd2)
c(F = round(an2$`F value`[1], 2), p = round(an2$`Pr(>F)`[1], 2)) F p
0.38 0.54 round(tapply(bd2$distances, g2, mean), 3) A B
0.243 0.234 This is what a trustworthy result looks like. PERMANOVA is strongly significant with an R squared of 0.46, and betadisper is non-significant (p around 0.54) with near-identical spreads (0.24 and 0.23). The centroids genuinely moved and the clouds are equally tight, so the PERMANOVA result means what you want it to mean.
The picture makes the contrast immediate.
pco <- function(D, g, lab) {
cs <- cmdscale(D, k = 2)
data.frame(ax1 = cs[, 1], ax2 = cs[, 2], grp = g, panel = lab)
}
od <- rbind(pco(D1, g1, "dispersion artefact"),
pco(D2, g2, "true location shift"))
od$panel <- factor(od$panel, levels = c("dispersion artefact",
"true location shift"))
cent <- aggregate(cbind(ax1, ax2) ~ grp + panel, od, mean)
ggplot(od, aes(ax1, ax2, colour = grp)) +
geom_point(alpha = 0.6, size = 1.8) +
geom_point(data = cent, size = 5, shape = 17) +
facet_wrap(~panel, scales = "free") +
scale_colour_manual(values = c(A = "#275139", B = "#cda23f"), name = "group") +
labs(x = "PCoA 1", y = "PCoA 2") +
theme_minimal(base_size = 12) +
theme(panel.grid.minor = element_blank(),
strip.text = element_text(colour = "#16241d", face = "bold"),
plot.background = element_rect(fill = "#f5f4ee", colour = NA),
panel.background = element_rect(fill = "#f5f4ee", colour = NA))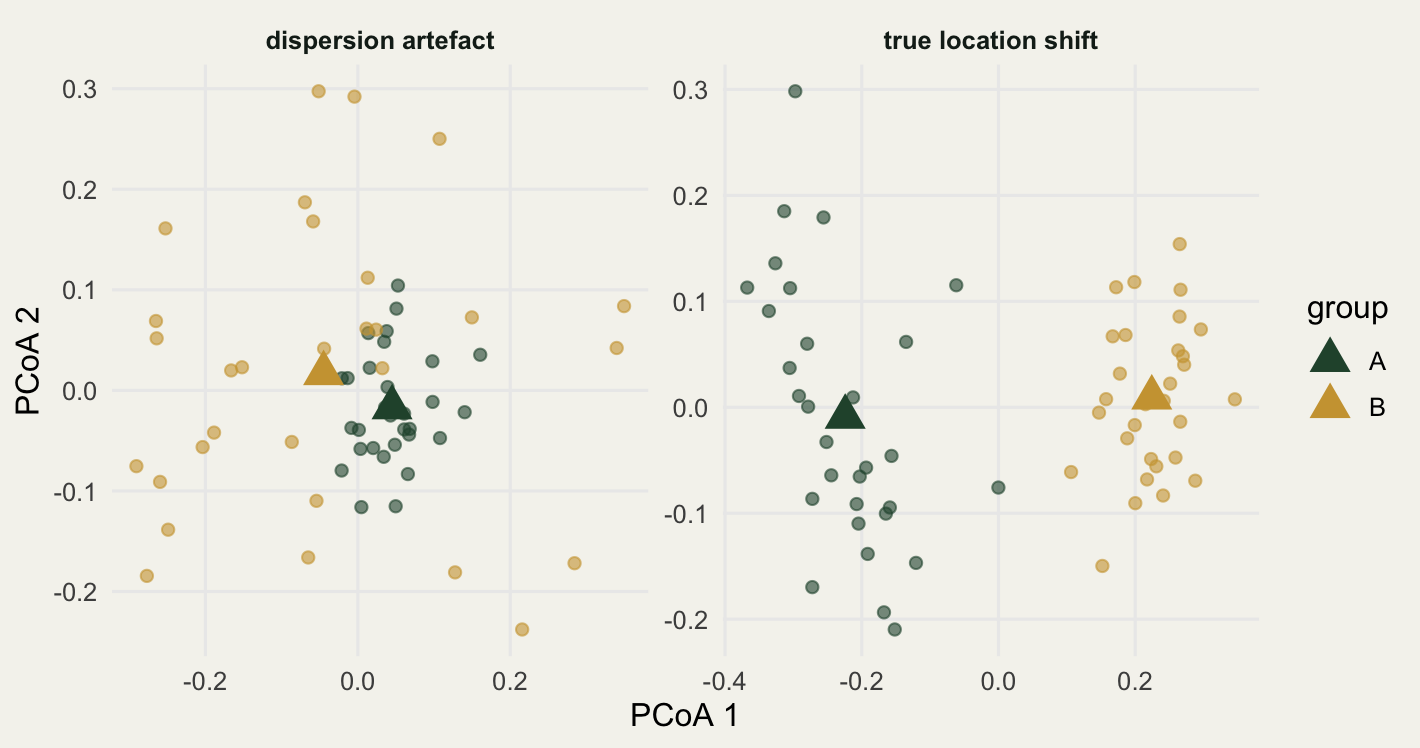
The triangles are the group centroids. On the left they sit almost on top of each other, yet the gold cloud sprawls while the green one is compact: that asymmetry is the whole of the PERMANOVA signal. On the right the centroids are pulled clearly apart and the two clouds are equally tight. The betadisper distances draw the same conclusion as a one-dimensional summary.
dd <- rbind(
data.frame(dist = bd1$distances, grp = g1, panel = "dispersion artefact"),
data.frame(dist = bd2$distances, grp = g2, panel = "true location shift"))
dd$panel <- factor(dd$panel, levels = c("dispersion artefact",
"true location shift"))
ggplot(dd, aes(grp, dist, fill = grp)) +
geom_boxplot(width = 0.55, colour = "#16241d", outlier.size = 0.8) +
facet_wrap(~panel) +
scale_fill_manual(values = c(A = "#275139", B = "#cda23f"), guide = "none") +
labs(x = NULL, y = "distance to centroid") +
theme_minimal(base_size = 12) +
theme(panel.grid.minor = element_blank(),
strip.text = element_text(colour = "#16241d", face = "bold"),
plot.background = element_rect(fill = "#f5f4ee", colour = NA),
panel.background = element_rect(fill = "#f5f4ee", colour = NA))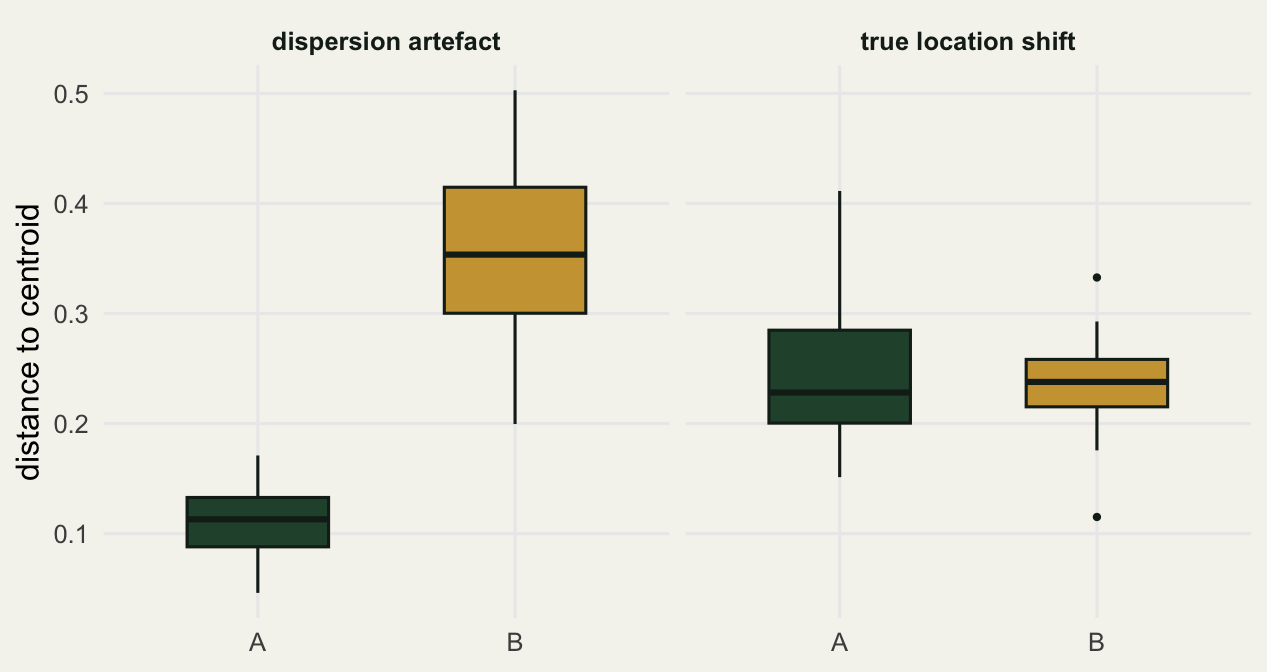
The rule is simple: never report a PERMANOVA without the matching betadisper. A significant PERMANOVA with a significant dispersion test is ambiguous, and you must say so. A significant PERMANOVA with a non-significant dispersion test is a clean location difference.
Mistake 2: the wrong dissimilarity
PERMANOVA works on whatever dissimilarity matrix you hand it, and the choice is not a formality. Euclidean distance on raw abundances, the implicit default if you reach for dist, is almost always wrong for community data. It treats two joint absences as evidence of similarity (the double-zero problem), it is dominated by the most abundant species, and it has no upper bound, so a single superabundant taxon can swamp everything else.
D_bray <- vegdist(Y2, method = "bray") # appropriate for composition
D_euc <- dist(Y2) # raw Euclidean, the wrong default
c(bray_R2 = round(adonis2(D_bray ~ g2, permutations = 999)$R2[1], 3),
euclidean_R2 = round(adonis2(D_euc ~ g2, permutations = 999)$R2[1], 3)) bray_R2 euclidean_R2
0.458 0.359 On the very same data the two measures attribute different amounts of variation to the grouping (0.46 against 0.36 here), and on more skewed data they routinely disagree about significance itself. Use Bray-Curtis or Jaccard for abundances, Jaccard or Sorensen for presence-absence, or a Hellinger transformation followed by Euclidean distance if you want a transformation-based RDA-compatible metric. Match the dissimilarity to the data; do not let dist decide for you.
Mistake 3: ignoring the design when permuting
PERMANOVA gets its p value by shuffling labels. The default shuffles freely, which is only valid if every sampling unit is exchangeable under the null. The moment your design has structure, repeated measures on the same plots, subplots nested in sites, a blocked or split-plot layout, free permutation tests the wrong hypothesis and is usually anticonservative, handing you significance you did not earn.
The fix is to restrict the permutations to the exchangeable structure using how from the permute package, which adonis2 accepts directly.
library(permute)
# subplots nested in 'site'; test treatment by permuting only within sites
ctrl <- how(blocks = site, nperm = 999)
adonis2(D ~ treatment, permutations = ctrl)Restricting the permutations leaves the observed pseudo-F unchanged but builds the null distribution from rearrangements the design actually permits, which is the only valid reference. If you have repeated measures or nesting and you are permuting freely, your p value is answering a question you did not ask.
Mistake 4: unbalanced groups plus unequal dispersion
The dispersion problem of mistake 1 gets sharper when group sizes are unequal. Anderson and Walsh’s simulations show that with unbalanced designs the tests are too liberal when the smaller group is the more dispersed one, and too conservative when the larger group is. In other words, a small, noisy group can manufacture a significant PERMANOVA out of pure dispersion, and you will not see it unless you have checked balance and run betadisper. Aim for balanced designs where you can; where you cannot, treat a significant result with heterogeneous dispersions and unequal n with real suspicion, and lean on the dispersion test to interpret it.
A short checklist
Before you believe a PERMANOVA: run betadisper and report it alongside, every time. Confirm your dissimilarity suits the data type rather than accepting the Euclidean default. Permute within the structure your design imposes, not freely, whenever units are non-independent. Check whether your groups are balanced, and be extra careful when they are not. And read the R squared, not just the p value: a significant test explaining a sliver of variation, next to a loud dispersion signal, is a dispersion artefact until proven otherwise.
PERMANOVA is an excellent tool. It just answers a narrower question than its p value appears to promise, and the gap between the two is where most of the mistakes live.
References
Anderson 2001 Austral Ecology 26(1):32-46 (10.1111/j.1442-9993.2001.01070.pp.x)
Anderson 2006 Biometrics 62(1):245-253 (10.1111/j.1541-0420.2005.00440.x)
Anderson and Walsh 2013 Ecological Monographs 83(4):557-574 (10.1890/12-2010.1)